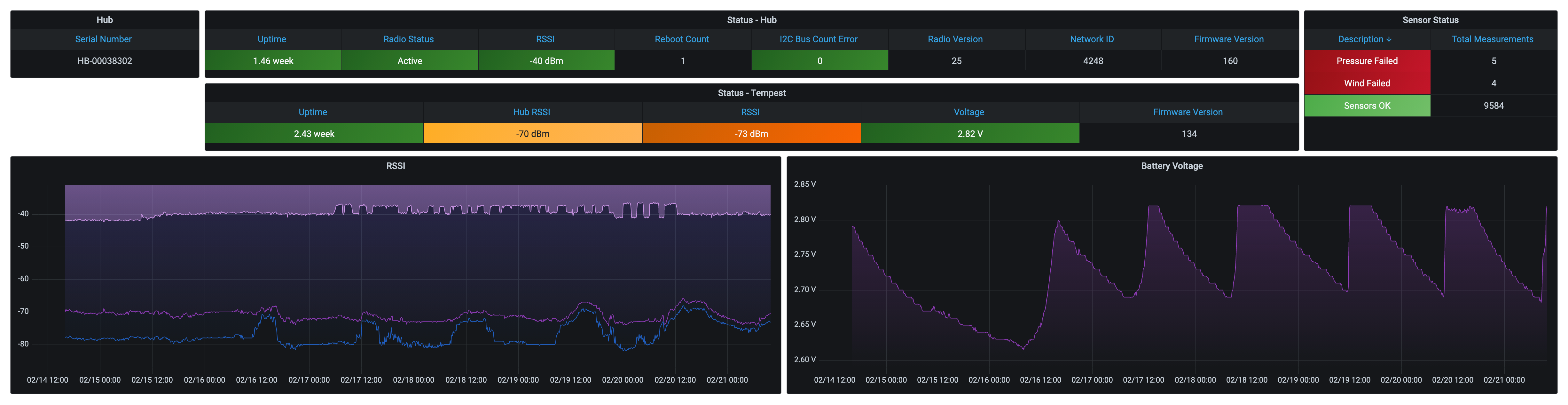
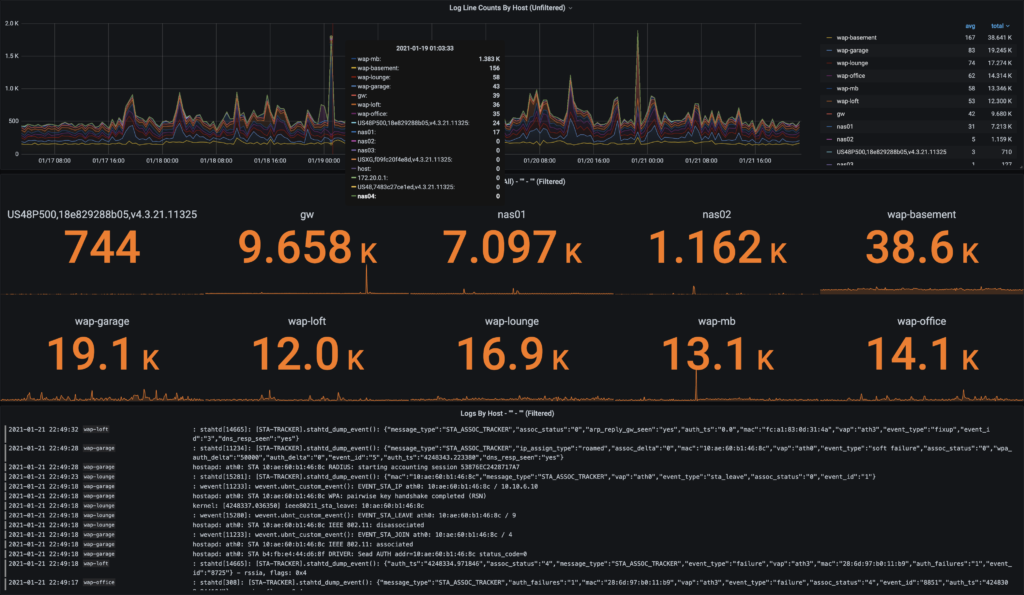
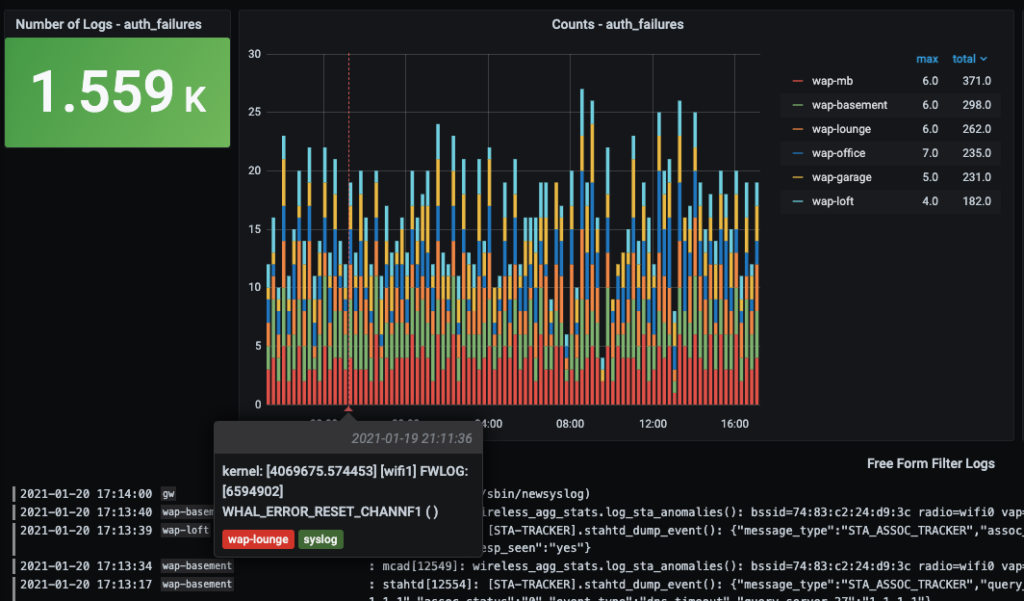
I started noticing some gaps in my home-lab monitoring solutions this week, but I didn’t pay much attention until I looked at it over time.

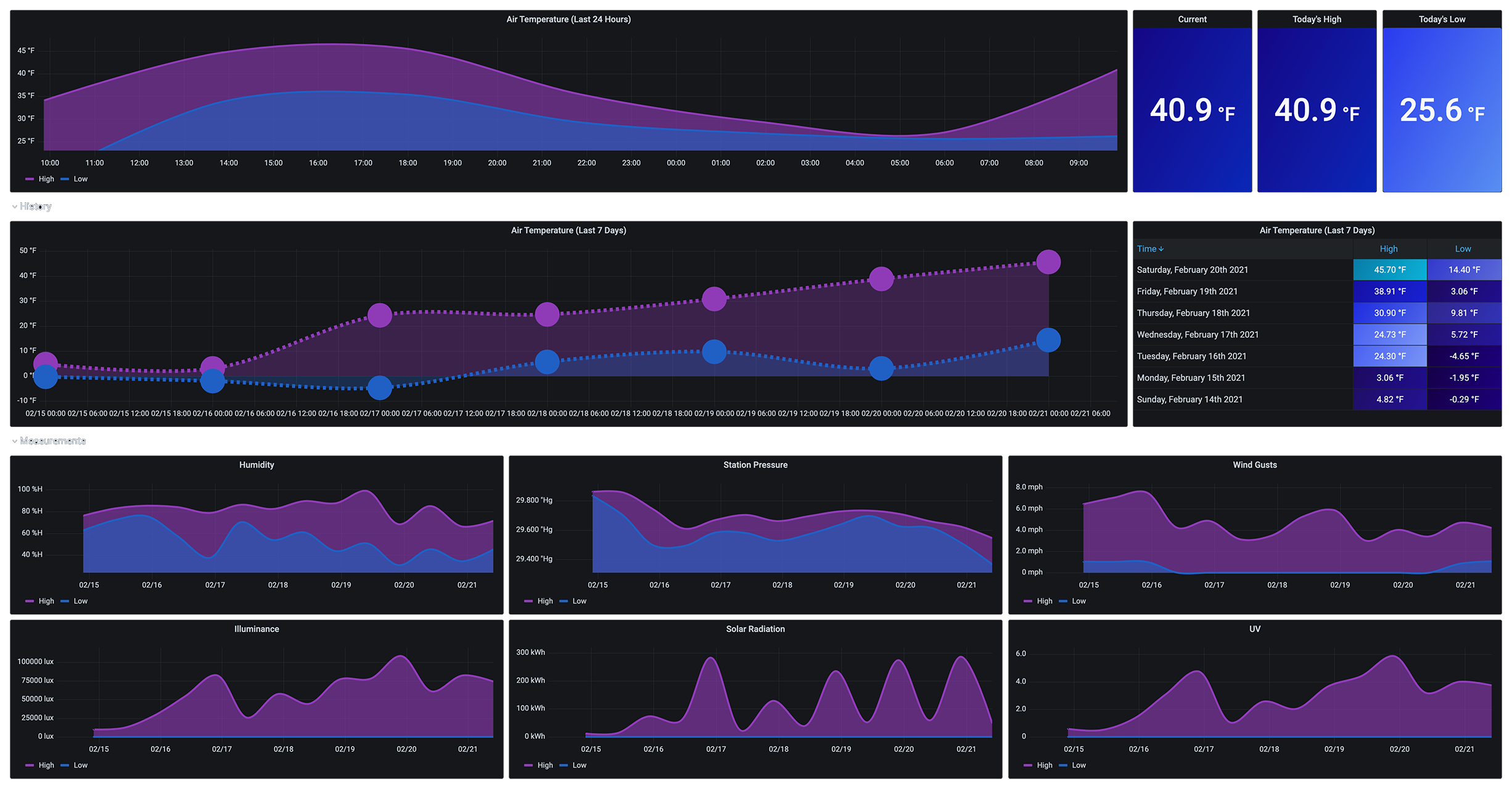
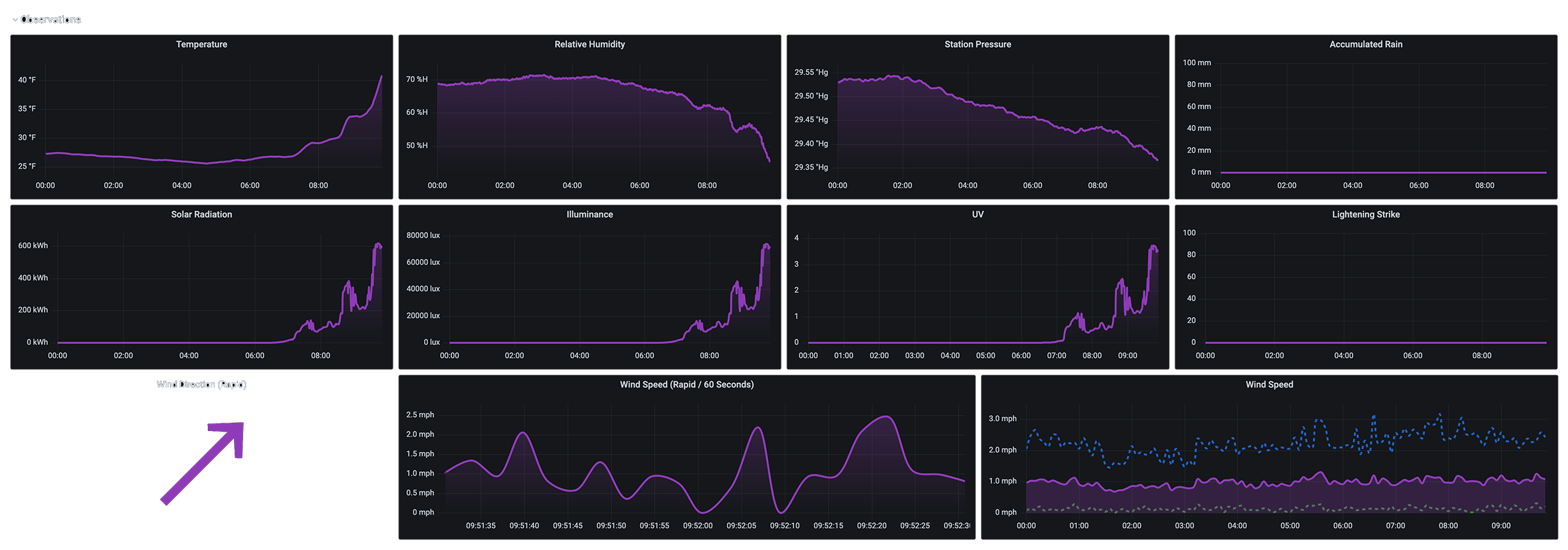
My SmartThings Prometheus exporter reaches out to the SmartThings API every 60 seconds and populates the status and metrics for each of my devices. I can make some nice Grafana dashboards that show battery levels, contact, motion, & switch status, power usage, temperature, and thermostats. But there’s nothing worse than seeing null values in my data!! UGH!!! (It makes for some seriously ugly graphs and missed alerts – unless you’re connecting null values…)
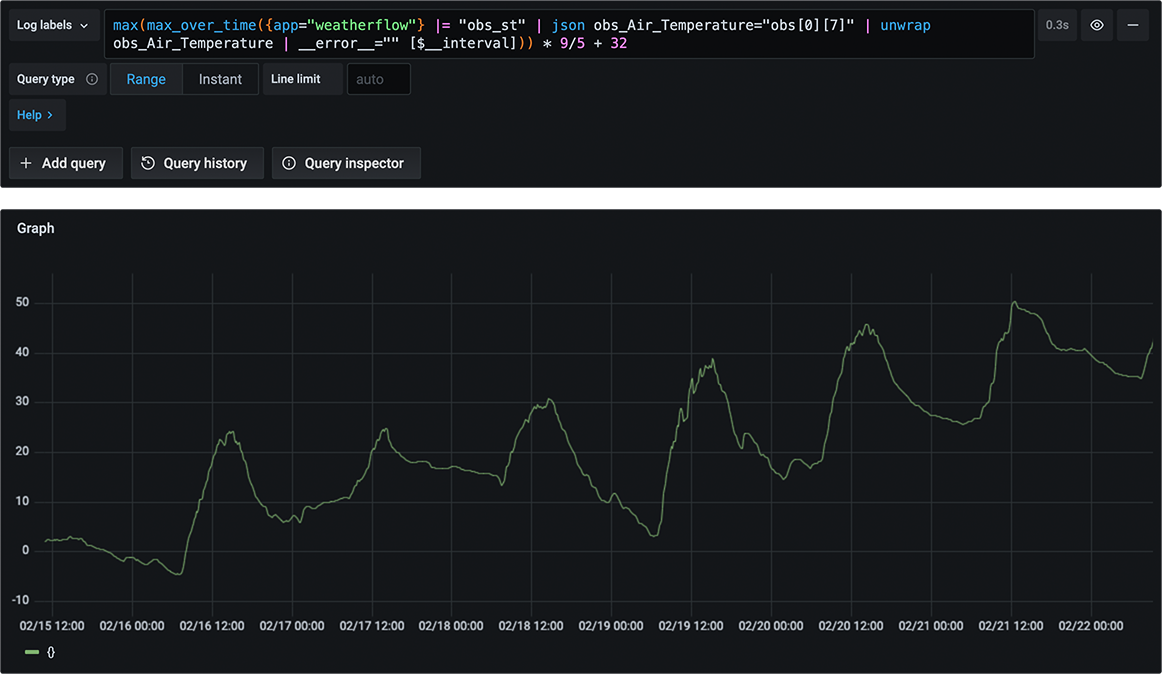
Because I also use Grafana’s Loki Docker Driver Client, I could quickly take a current and historical view of the logs from my SmartThings exporter. It wasn’t looking good:
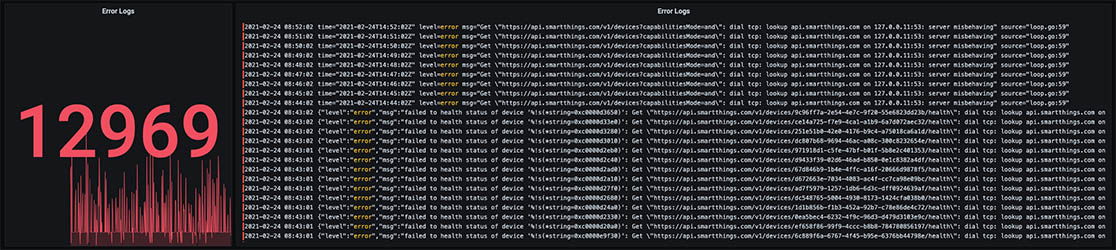
Something started kicking off a lot of errors around the 19th of February. And what are all these messages?
dial tcp: lookup api.smartthings.com on 127.0.0.11:53: server misbehaving" source="loop.go:59"
Specifically – looking up a server name on port 53 points to my local DNS server. To start troubleshooting – I tried doing some command line DNS lookups first:
# nslookup api.smartthings.com Server: 10.10.3.80 Address: 10.10.3.80#53 Non-authoritative answer: Name: api.smartthings.com Address: 3.131.74.134 Name: api.smartthings.com Address: 13.59.226.110 Name: api.smartthings.com Address: 3.137.134.173 Name: api.smartthings.com Address: 3.131.168.20 Name: api.smartthings.com Address: 18.220.168.164 Name: api.smartthings.com Address: 3.140.46.118 Name: api.smartthings.com Address: 3.13.133.255 Name: api.smartthings.com Address: 3.131.79.130
That looked fine. So I tried running it a few more times just to be sure, and I quickly received a different response:
# nslookup api.smartthings.com Server: 10.10.3.80 Address: 10.10.3.80#53 ** server can't find api.smartthings.com: REFUSED
Refused huh? (I shall not be REFUSED!!)
Let me try a local network server:
# nslookup grafana01.tylephony.com Server: 10.10.3.80 Address: 10.10.3.80#53 ** server can't find grafana01.tylephony.com: REFUSED
Since I use and love Pi-hole as my local DNS and DHCP server, I quickly searched their forums and found a similar issue. But the response didn’t make sense in my case: “Pi-hole is not refusing it, your upstream is refusing to provide an answer.”
Pi-hole IS my upstream server!!
More digging in the forums revealed the most recent release notes for Pi-hole FTL v5.7 and Web v5.4. This caught my eye:
Inbuilt enhanced Denial-of-Service (DoS) protection
Hence, we decided to implement a customizable rate-limiting into FTL itself. It defaults to the rather conservative limit of allowing no more than 1000 queries in a 60 seconds window for each client. Afterwards, any further queries are replied to with empty replies with the status set to REFUSED. Both the number of queries within the window as well as the window size can be configured by the user. It is important to note that rate-limiting is happening on a per-client basis. Other clients can continue to use FTL while rate-limited clients are short-circuited at the same time.
Because I monitor many of my servers with Grafana, Prometheus, and InfluxDB, I often ping DNS. It’s around 5 million times a day. And I did just update my Pi-hole servers. A look back at my Pi-hole DNS stats shows more of this trend over time, both before and after this update.
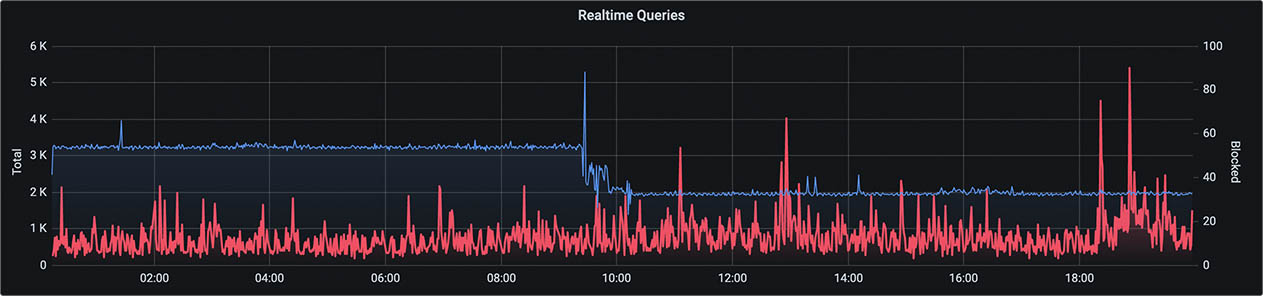
Since the server I have running my SmartThings exporter also runs a lot of other exporters and metrics collectors, Pi-hole was rate-limiting that client.
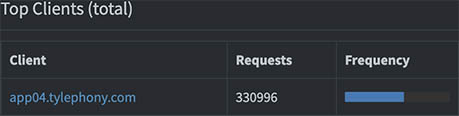
Thankfully, an easy fix:
Rate-limiting can easily be disabled by setting RATE_LIMIT=0/0 in /etc/pihole/pihole-FTL.conf. If I want, say, to set a rate limit of 1 query per hour, the option should look like RATE_LIMIT=1/3600.
So – any lessons learned?
- Read the release notes before deploying any updates. (Nope!)
- Limit the rate interval or the number of metrics and exporters to ease the number of DNS queries. (Nope!)
- Set up default error alerting to catch problems sooner. (Soon!!)
Happily – no more gaps…